创建软链接: ln -s 被指向的文件 软连接文件
创建硬链接: 上述指令去掉-s
删除软连接: rm -rf qtool/ 说明:相对路径qtool是一个软连接,删除qtool下面的东西。但是保留qtool文件。
rm -rf qtool 说明,文件qtool以及底下的东西一起删除
创建软链接: ln -s 被指向的文件 软连接文件
创建硬链接: 上述指令去掉-s
删除软连接: rm -rf qtool/ 说明:相对路径qtool是一个软连接,删除qtool下面的东西。但是保留qtool文件。
rm -rf qtool 说明,文件qtool以及底下的东西一起删除
前言:
linux内核是一个很伟大的东西。。。(好吧~我居然用“伟大”来形容了linux内核),不过说实话,内核代码绝对是c语言中经典的经典。里面的一些设计思想都值得反复推敲、琢磨(虽然我还看不大懂,在啃过程中)。。按照我导师的话来说:写linux内核的那帮人绝对是顶级聪明的人。
看聪明人的作品,熏陶 熏陶自己。
我们今天关注问题如下:why linux的文件系统设计group这个概念。有什么好处呢?linux文件系统已经够复杂了,为什么还要加上group这个管理单元?
那天导师问这问题时,我硬是没怎么反应过来,说了几个答案,但都没说到点上,这儿我总结一下:
面对问题的思考方法:
从多角度思考这个问题:
从用户角度:方便用户容量的扩充或减少
很明显,有了group这个概念,我们的元数据区、数据区可以一个版块一个版块地管理,如果用户容量扩充,只需要在现有group后增加几个group,然后修改super block,GDT(块组描述符)等就可以了。减小容量也是如此;试想一下如下没有group这个概念,若要扩容,则inode bitmap,data bitmap,inode table所占的空间都要变大,那么整个数据区都要向后迁移,代价太大。
从计算机性能角度:一次IO能抓取所需元数据,提高访问速度
首先我们要知道,在默认的配置中,一个group单元中的block bitmap的个数为32768,这个在格式化磁盘时,可以在输出信息上看到信息:32768 blocks per group。所以说block bitmap所需要的占用的存储空间大小刚好为1个block大小,即4k,所以说在一次IO读操作,我就可以把当前访问数据的bitmap区域的元数据一次性缓存,由于与访问的局部性,一段时间访问的数据很大概率都是位于这个block的,所以需要多次访问元数据,而这些元数据系统都cache住了,故性能得到很好地提高。
上面说的是block bitmap为4k,默认一个group中inode bitmap为1k。也是可以一次IO都缓存下的。而且data区域4k*8*4k= 128M,这个大小都是一次调入Mem可以缓存下的。所以极大提高了cache命中率,也就提高了访问速率。
其实上述的解释都可以类比于一个概念:对齐。在计算机系统结构中,一定要建立一个对齐的概念,对齐的概念我通过两个例子稍微解释。
例1:一个数据结构如果放在未对齐的内存中,则会引起两次访存操作。
例2:放在磁盘上一个4k的文件,如果跨了两个block,那么要进行两次访问disk的操作,效率大打折扣。
所以说计算机系统结构中,对齐是效率的一个关键点所在。
从磁盘寿命的角度:写均匀,延长寿命
元数据、数据写的区域因为布局方式的因素,因而把写均匀到了磁盘的各个区域。个人感觉有一定的延长寿命作用。
关于group概念还能带来什么好处,欢迎留言!
补充:
这里对group概念稍做介绍,文件系统结构图如下:
文件系统是以分区为单位的,所以说一个分区上的所有group的文件系统类型都相同。
整个分区group的inode是连续编号的,给定一个inode编号,可以通过取模、取余的方式可以知道该inode为那个group上的第几个inode。inode编号从1开始,故所在块组bg=inode_num -1)/ ext4_super_block.s_inodes_per_group
所在 块组的index
index=(inode_num -1) % ext4_super_block.s_inodes_per_group
1.dmesg介绍
在dmesg里我们可以查看到开机信息,printk产生的信息等。若研究内核代码,在代码中插入printk函数,然后通过dmesg观察是一个很好地方法。
2.dmesg输出含义
dmesg 输出的数字含义是什么,纠结了一会儿,下面给出解释
终端输入dmesg,可以看到每行最开始显示的是一个综括号,里面的数字为timestamp,时间戳,该时间指示的系统从开机到现在的运行时间,单位为s 秒。
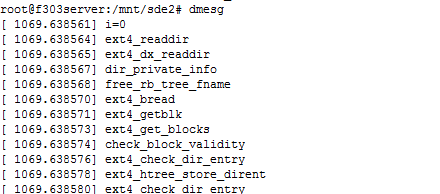
图1
3.dmesg -c
在显示的同时,clean掉dmesg缓存中信息
4.dmesg -T
以当前时间的方式显示时间信息,而不是图1所示的开机时间
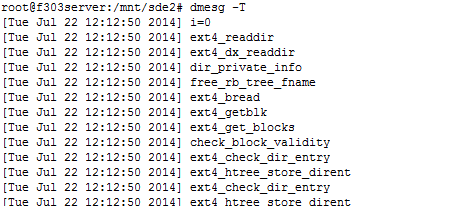
图2
3 dmesg -d
显示dmesg中两条打印信息的时间间隔
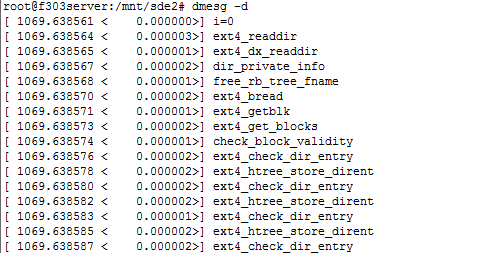
图3
我们可以计算,上一行的时间戳 + 下一行的间隔 = 下一行的时间戳
例如:第一行和第二行,1069.638561 + 0.000003 = 1069.638564 这里的时间单位为秒
4.dmesg -d -T
-d和-T参数混合使用,效果可想而知
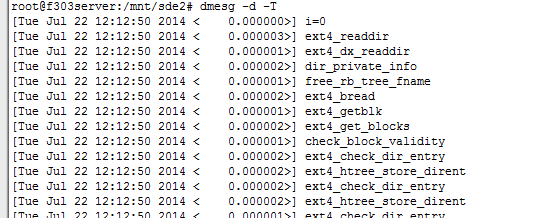
图4
5.dmesg | tail 显示dmesg最近一次的输出
由上面我们可以看到dmesg可以让我们获得很多信息,包括函数进入时间等,可以利用dmesg原本已有的功能进行辅助分析。dmesg 很~\(≧▽≦)/~赞
1.gdb 编译、运行
编译:gcc -g -Wall hello.c -o hello
调试:./hello
2.设置断点
b 函数名
b 行号
上述b为break的简写
设置好断点后,可以通过info break查看设置的断点:

3.continue指令
运行到断点停止后,可以输入continue使代码继续运行
4.watch指令
watch s 变量s发生变化时中断 运行时 continue 继续执行遇到s变化时会显示old value以及new value以及watchpoint 号。如下:
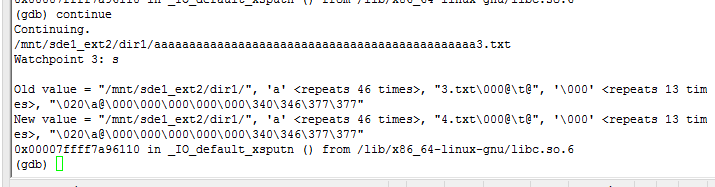
顺便说一句,info break也可以看到watch对应的编号
5.run 运行
run 运行程序,若有参数,则在run后面加参数
6.print 查看变量
print value 查看value的值
7 清除断点
clear n 清除第n行的断点
delete breakpoint 1 其中1是breakpoint的num,该num可以通过info break查看
8.disable 清除watch点
disable 4 其中4是watch点的num,该num同样可以通过info来查看。
如下如在输入disable 4之前,Enb状态为y,输入后状态为n

之后要是用上了什么实用的gdb指令再完善该文章
本文借鉴博客如下:
http://www.cppblog.com/deercoder/articles/109274.html
背景:
最近在研究将文件系统模块化,将模块化的文件系统插入到内核中后想看看有关自己模块的信息。于是有了本文。
知识点:
在成功插入模块后,即ismod *.ko成功后。在/sys/module和/proc/modules中都包含模块信息
1./proc/modules中模块信息
输入指令cat /proc/modules,显示如下:
下面以:ext2 68558 0 - Live 0xffffffffa01fd000这一行为例,说明各列含义
其中ext2(模块名) 68558(占用内存大小) 0(引用该模块基数) - Live(模块可用) 0xffffffffa01fd000(模块的起始地址)
2./sys/modules中模块的信息
输入
cd /sys/modules
ls
可以看到所有对应的模块
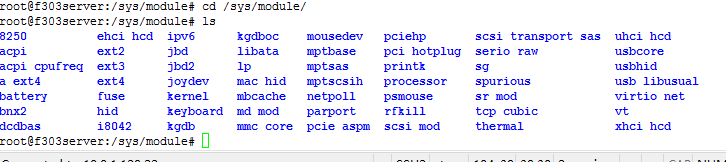
打开其中一个模块,以ext2为例,可以看到包含如下内容
inistate:记录模块活动
notes :貌似记录本模块信息
refcnt: 引用模块数
sections:
srcversion: 模块版本号,类似于模块ID
在linux系统中fdisk -l可以看到所有磁盘的分区情况。含有系统的分区有 * 号标志,如下:
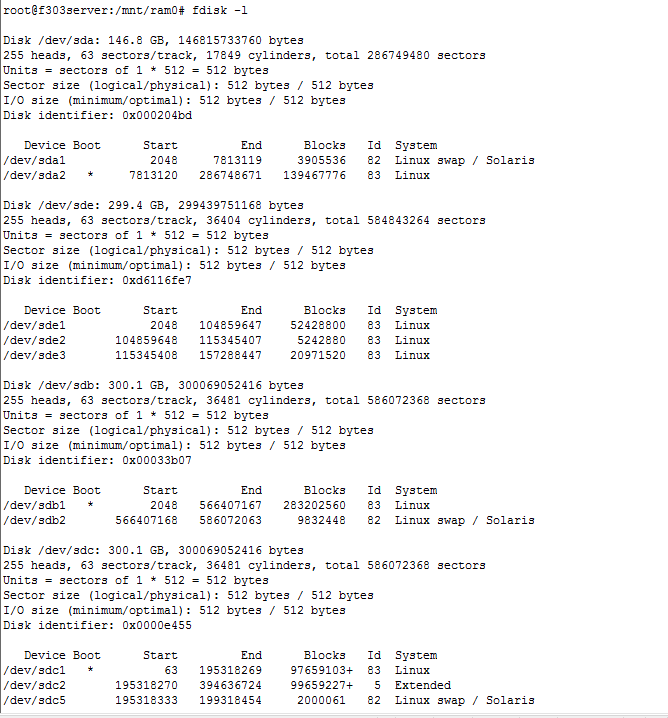
分区太多,上图为显示完全。但在已经显示的分区中,多个分区的Boot列中都有* 号标志,那么当前的系统是运行在哪个分区的呢?
注意:根目录所在的分区就是当前系统所在的分区。输入 df -h,可以观察到根目录所在的分区。
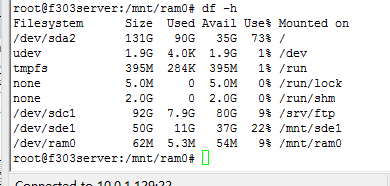
如上图所示:与根目录相应的分区为/dev/sda2,故当前系统运行在分区/dev/sda2上。
1.cat /proc/cpuinfo 查看cpu型号、频率
2.cat /proc/meminfo 查看内存大小
3.dmidecode -t memory 查看DDR2 DDR3
4.cat /etc/issue 查看Ubuntu版本
5.cat /proc/version 查看内核版本
6.uname -a 查看linux位数 x86_64为64位,其余32位。
参考博文:
http://www.cnblogs.com/joeblackzqq/archive/2011/04/11/2013010.html
函数原型
fopen:返回的是FILE *
FILE * fopen(const char * path,const char * mode);
open:返回的是int
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
两者区别
1.返回值
fopen返回FILE * ,是ANSIC标准中的c语言库函数,可理解为对open的一层封装。返回的是文件流,因为设备不可以当成流式文件,故设备的打开只可以用open。
open返回int,open是系统调用,返回文件句柄,文件的句柄是文件在文件描述符表中的索引。open可以打开设备,也可以打开普通文件。
2.缓冲机制
fopen有缓冲机制,使用FILE这个结构保存缓冲数据。open没有缓存机制,每次读操作都直接从文件系统获取数据。简单来说:fopen有缓冲,open无缓冲
缓冲文件系统特点:在内存开辟一个“缓冲区”,为程序每一个文件使用,读写都要经过缓冲区。
非缓冲文件系统:借助文件结构体指针对文件进行管理,依赖于操作系统,是系统级的输入输出,不设文件结构体指针
3.fopen是在open的基础上扩充而来的,大多数情况用fopen
4.fopen与 fread和 fwrite配合使用。open与read,write配合使用
5.fopen属于高级IO,open属于低级IO
6.一般用fopen打开普通文件,open打开设备文件
7.fopen 可移植,open不能
本文参考:
http://jesserei.blog.163.com/blog/static/121411689201032015129673/
http://blog.csdn.net/liangxanhai/article/details/7749170
函数原型
int fsync(int fd);
sync();
函数区别:
sync函数将所有修改过的块缓冲区排入写队列,然后返回,不等待实际写磁盘操作
fsync只对参数中的文件描述符fd指定的单一文件起作用,并且等待写磁盘操作结束,在返回。故fsync可以应用于数据库这样程序,这种应用程序需要确保将修改过的块立即写到磁盘上。
本文参考:
http://blog.csdn.net/wallwind/article/details/7461701
首先来看O_DIRECT参数适用要求:
O_DIRECT
Try to minimize cache effects of the I/O to and from this file. In general this will degrade performance, but it is useful in special situations, such as when applications do their own caching. File I/O is done directly to/from user space buffers. The I/O is synchronous, i.e., at the completion of a read(2) or write(2), data is guaranteed to have been transferred. Under Linux 2.4 transfer sizes, and the alignment of user buffer and file offset must all be multiples of the logical block size of the file system.
上述也就是说buffer的地址以及大小都必须是block size 的整数倍,buffer的大小可以通过代码设定,但buffer的首地址的控制,需要通过posix_menalign()函数来数据对齐
ps:上述所说的buffer地址为block size整数倍,就是数据对齐的概念
int posix_memalign (void **memptr, size_t alignment, size_t size);
成功会返回size字节的动态内存,且内存地址为alignment的整数倍
下面看具体代码
#define __USE_GNU
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include <unistd.h>
#include <pwd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main(void)
{
int fd;
int i;
const int SIZE = 4096*10;//(每次写入文件数据块大小)
char* buffer;
char s[100];
int pagesize=getpagesize();
printf("pagesize = %d\n",pagesize);
pid_t my_pid;
my_pid=getpid();
printf("%d\n",my_pid);
if(mkdir("dir1",S_IRWXU|S_IRGRP|S_IXGRP|S_IROTH)<0)//创建新目录
{
printf("mkdir failed\n");
return -1;
}
if(0 != posix_memalign((void**)&buffer, 4096, 40960)){
printf("Errori in posix_memalign\n");
}
for(i=0;i<10;i++)
{
sprintf(s,"./dir1/aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa%d.txt",i);
printf("%s\n",s);
fd=open(s, O_RDWR | O_CREAT | O_DIRECT);
write(fd,buffer,SIZE);
fsync(fd);
close(fd);
}
free(buffer);
sync();
return 0;
}
上述代码有几个点:
1.mkdir创建目录
2.posix_menalign()进行数据对齐
3.获取block size,即内存页大小getpagesize()
4.编译时需要gcc -o blktrace_study1 blktrace_study1.c -D_GNU_SOURCE
5.open函数返回的为int ,区别fopen函数返回FILE *
6.fsync和sync区别见另一篇博客
Host by is-Programmer.com | Power by Chito 1.3.3 beta | Theme: Aeros 2.0 by TheBuckmaker.com