原则,所有的指令都是要在exc退出后的模式才能使用;
u -- 回退,理解为windows的ctrl+z
w -- 往下查找,一直按右键移到一行的某个位置很慢,可以用w来加速
5、w -- 先按5,再按w,往后 挑5个,这个在上一条基础上移动更快
挑5个,这个在上一条基础上移动更快
b -- 往上查找,与w相反
5、b -- 往下查找,与5、w相反
/core -- 按n查找下一个,按N查找前一个
yy、 p -- 复制当前的行
3yy、p -- 复制当前开始后的3行
dd -- 删除当前行
原则,所有的指令都是要在exc退出后的模式才能使用;
u -- 回退,理解为windows的ctrl+z
w -- 往下查找,一直按右键移到一行的某个位置很慢,可以用w来加速
5、w -- 先按5,再按w,往后挑5个,这个在上一条基础上移动更快
b -- 往上查找,与w相反
5、b -- 往下查找,与5、w相反
/core -- 按n查找下一个,按N查找前一个
yy、 p -- 复制当前的行
3yy、p -- 复制当前开始后的3行
dd -- 删除当前行

本文为https://ext4.wiki.kernel.org/index.php/Ext4_Howto的翻译。粗略介绍ext4的特性。
EXT4 特性:
兼容性:
Ext3文件系统可以以ext4的形式挂载,且不需要改变磁盘的布局格式。但是可以通过在只读模式下运行一些命令让ext3文件系统具备ext4文件系统的一些优势。
文件系统、文件更大:
下面是ext3、ext4文件系统总大小和单个文件大小的最大值
Ext3 16Tb 2Tb
Ext4 1Eb 16Tb
若要支持块数目大于2^32个块的文件,文件系统必须具备extents。因为block map只知道32bit的block号。在e2fsprogs1.42.9中,这个功能由mke2fs使能控制。
子目录扩展
在Ext3中,单个目录下的文件及其目录数目不超过32000个。EXT4将这个限制增大了倍数
Extents
传统的如ext3,管理一个文件的不同块使用的是block机制,这对于大文件来说是效率很低的,比如大文件的截断、删除操作。Extent就是一系列的连续的block。它的含义是说:数据在接下来连续的n个blocks中,这样就避免了一个一个block的描述。例如:一个100M的文件在传统ext3的方式下需要存放在256000个block中,terrible。现在ext4就可以由几个extents来管理。Extents不仅提高了性能,而且可以改善碎片的情况(extents优先考虑磁盘上连续的布局方式)。
多blocks的分配(主要说malloc)
当ext3需要将数据写入磁盘时,块分配器会决定分配那个空闲块给要写入的数据。当时ext3的块分配器一次性只会分配一个块,也就是说如果一个100M的文件要写入磁盘,那么快分配器要调用25600次。这不仅十分低效,更可怕的是,由于分配器无法知道一共要分配多少个块,而只是机械的一个个块的分配,所以说无法从磁盘的角度实现磁盘优化分配利用。EXT4使用multiblock allocator(malloc),这个功能能实现调用一次而分配多个块,从而减小了开销。这提高了性能。尤其是在结合extents和delay allocation策略。这个特性不会影响磁盘的格式特性。此外,ext4的block、inode分配器有其他的优化。
延迟分配
延迟分配是在XFS,ZFS,btrfs、Reiser 4文件系统中的特性。该策略就是尽可能晚地分配blocks,这点与传统的文件系统(如ext3)相反,ext3的策略是,尽可能早地分配blocks。举一个例子:调用write(),文件系统会立马分配好数据要写如磁盘的地点,即便数据当前在cache中,没有写入磁盘。这种方式有缺陷:比如说,一个进程连续写一个文件,文件缓慢增大,故系统会不断地的给数据分配空间,因为块分配器不知道到底多少够用,所以由于write函数催使而不断分配。而延迟分配机制会延时数据块的分配,在数据从cache被替换出来时,块分配器才会真正分配块写在磁盘中的位置。这样就在预置要分配块的总数的前提下,就能最优化地分配块,使磁盘空间得到最好的利用。延迟分配与前面两种机制结合使用有很好的效果,因为许多文件最终从cache写入磁盘时,会以extents方式,而该方式的blocks是通过malloc,即多blocks分配机制申请得到的。
快速的fsck
Fsck是一个很慢的操作,尤其在第一步:检查文件系统中所有的节点。在ext4中,在每个group的inode 表后会存储一个未使用inode节点的清单(该清单为了保证安全,有校验信息),所以fsck操作不会去检查inodes,fsck的实验结果表明,根据inode使用数目的不同,fsck时间提高了2到20倍。这里不许注意的是,是fsck,而非ext4,建立的未使用inode节点清单。这就意味着必须运行fsck来建立未使用inode节点清单,下一次运行fsck才会变快(需要运行fsck完成ext3到ext4的转变)。“flexible block groups (灵活的块分组)”也与加速fsck有关系
日志校验和
日志是磁盘最常用的一部分,所以这一块更容易出现故障。而且一个从损坏日志的恢复行为会导致文件系统的更大损坏。Ext4为日志块的数据做了校验,从而可以知道日志块是否损坏。日志校验还有一个附加好处:它使得ext3这种两阶段的日志提交系统,变成了单阶段提交,在一些情况下加速了文件系统的操作,性能提高了20%,所以可靠性和性能都提升。(注意:提高性能的部分:异步log,在缺省默认状态下是关闭的,在稳定性改善后,之后的版本会支持该功能)
“无日志”模式
日志模式虽然提高了文件系统的可靠性,但是存在开销。在ext4中,可以关闭日志模式,性能可以得到一定提升
在线碎片整理
(这个功能正在开发,之后的版本会支持该功能)。虽然延迟分配、extents、多块分配能减少碎片,但是碎片仍然会有。举一个例子:在一个目录里写 了三个文件,这三个文件连续的放在磁盘上。某天,你需要对中间的文件追加写,但中间文件空间不够了,这是,中间文件追加部分就只好碎片化地存在磁盘另一个位置了。(作实验)这样会引起一个seek操作,或者需要把中间文件全部内容再连续的存放在一个空间足够的磁盘位置(这样导致了若一个操作需要读取该目录下三个文件,就需要又一次seek操作)。另外,文件系统只关心特定的碎片,比如说boot相关的的需要连续
Inode相关特征
更大的inode节点:ext3支持可配置的inode节点大小(通过mkfs的 -I 参数),但是inode大小的缺省值128bytes。Ext4文件系统inode大小的缺省值是256bytes。Inode扩展的空间用于存储一些额外的域,如纳秒级时间戳、inode版本等,剩下的空间用来存储ext4的一些扩展属性。这会使得对这些属性的访问变快,对于一些需要用到拓展属性的应用,访问速度会增大3至7倍。
当一个目录创建的时候,inode预留空间会预留几个inode,估计inode会在短时间内被用到,即在目录中创建文件时要用到。这个措施能提高性能,因为在目录中创建新文件时可以直接使用预留的inode。文件的创建、删除都会效率更高
纳秒级的时间戳意味着inode中记录“更改时间”的数据可以使用到纳米级别,而在ext3中问秒级别
持久预分配
这个特征,在ext4最近的版本中实现,由glibc在不支持它的文件系统中仿真,她允许应用预分配磁盘的空间:应用告诉文件系统预分配空间,文件系统预分配必须的blocks以及相关数据结构,但是在应用真正写数据之前磁盘对应区域是没有数据的。对于P2P应用来说,他们需要有他们自己的“预分配机制”,分配的区域用于长达数小时甚至数天的下载,但是如果文件系统本身提供这个接口,那么预分配机制就会更加有效率。这个机制有几个用途:第一:避免P2P应用类程序自己进行低效的预分配,即用zeros来填充一个文件。第二:改善碎片问题,由于块一次性分配,所以会尽可能连续。第三:保证应用一直有其所需的空间,这点对应RT-ish类的应用很重要,若没有预分配,文件系统可能在操作的一般就使用完毕了(full)。这个特点在libc的posix_fallocage()中实现。
缺省状态有Barriers
这是在保证文件系统健全性和提高文件系统性能的权衡(你可以通过mount –o barrier=0,如果你在做benchmarking建议你试试)。LWN的一篇文章所说:文件系统的代码必须保证在写操作提交前,所有事物的信息都被写到了日志中。只是有顺序地进行写操作是不够的。中间层的cache中会有一些驱动器为了提高性能,重新定向IO操作的顺序。所以,文件系统必须在写提交前明确地告诉磁盘拿到所有的日志数据。如果提交请求先写,日志崩溃了,内核的I/O子系统通过barriers使其能恢复正常。Barrier禁止barrie后的写,除非该barrier之前的操作已经提交了。通过barrier,文件系统可以确保磁盘上的结构保持一致性。
转化ext3文件系统到ext4形式
可以将ext3的文件系统mount为ext4的形式,使用ext4的文件系统驱动。这样文件系统就可以使用延时分配,多块分配等。
下面指令从ext2文件系统转化为ext3文件系统(支持日志了)
tune2fs –j /dev/DEV
下面指令使ext3文件系统支持ext4文件系统特征
tune2fs –O extents,uninit_bg,dir_index /dev/DEV
注意的是,该指令一旦运行,文件系统就不能再被mount为ext3的文件系统了
运行上述指令后,必须运行fsck来修整一下磁盘上的结构
e2fsck –Fdc0 /dev/DEV
注意:
运行fsck可能会提示“一个或者多个组描述校验无效”,这个现象时可预见的,这也是为什么tune2fs需要fsck。
通过extents的特性,之后的新文件会以extents形式存在,但是老的文件不会变成extents形式。
如果将跟文件系统转化成ext4形式,你徐璈安装一些ext4可以运行的GRUB版本,启动项可能一开始可以启动,但是内核升级后,就可能不能启动了(按Alt+F+F来检查文件系统)
不建议使用e2fsprogs中的resize2fs来改变inode的大小
如果你在tunefs中去掉omit,你可以跳过fsck步骤。
扇区:扇区是在磁盘设备中,数据传送的基本单元,即硬件设备数据传送的单元。不允许传送小于一个扇区的数据,但是可以传送几个相邻扇区的数据。
块:块是VFS和文件系统传送数据的基本单元,也是映射层的映射单元。一个块对应着设备上一个或多个相邻的扇区。
页:内存的管理单元
块缓冲区:页中包含一个或多个块缓冲区,每个块缓冲区对应着上述一个块的内容,同一个页的块缓冲区可以不连续。
段:深入理解linux内核一书中描述段是一个内存页或者内存页的一部分,包含相邻磁盘的数据。但我赶脚这么理解不好。分段应该是方便内存的管理,为了满足用户(如程序员狗)在编程和使用方面的需求。引入段有如下好处:
1.方便编程,用户把自己的作业划分为若干个段,每个段都从0编制,有自己的段号和段内偏移。段为二维地址空间,而页为一维。
2信息组织、共享。在程序和数据的共享中,信息是以逻辑单位为基础的,如共享某个函数,分页同的页只存放信息的物理块,无实际意义,不便于共享。而段是有信息的逻辑单位,故方便共享。
3.信息保护。通过段越界等可以保护信息。
关于段页可以参考http://baike.baidu.com/view/3227088.htm
linux中的时间,我知道的有两种:系统时钟,硬件时钟
1.系统时钟
查看指令 date
修改指令1: date 月日时分年.秒
截图:
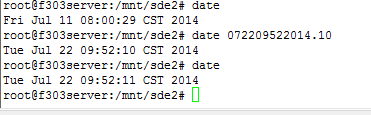
修改命令2: data -s 时:分:秒
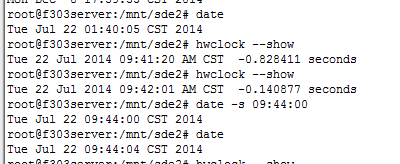
2.硬件时钟
查看命令: hwclock --show
修改命令: hwclock --set --date="月/日/年 时:分:秒"

1 include"" 和include<>区别。
前者在当前目录下找头文件,找不到再到系统目录下找,而include<>,直接在系统目录下找。所以include""涵盖了include<>
2.incline 声明函数,表示内联函数,内联函数即在调用处直接展开函数,而并非取调用函数,故不用保存现场,效率得到提高
3 宏定义简单函数,如#define TABLE_COMP(x) ((x)>0?(x):0)
优点:若函数调用,则要将函数的执行顺序转移到函数所存放的某个地址,将函数程序内容执行完后,在返回到转去执行原函数,故要保护现场。所以函数调用有时间、空间的开销,效率低。而宏是在预处理的地方把代码展开,五上述额外时间、空间开销。
缺点:容易产生二义性 如TABLE_MULTI(10+10)会(10+10*10+10),而非期望的400
4.递归代码简介,但缺点(1)递归是函数调用自身,函数调用存在时间消耗:每一次函数调用,需要在内存栈中分配空间以保存参数、返回地址及临时变量,栈的压入和弹出都需要时间。故递归实现不如循环。(2)调用栈溢出。每一次调用在内存栈中分配空间,每个进程栈的容量有限,若递归调用的层级太多,就会溢出
5.计算机表示小数(float和double)都有误差,故不能直接用等号判断两个小数是否相等。如果两个小数的差值很小,比如0.0000001,就可以认为它们相等
6.取模操作 % 操作数两边都应该为整形 如 12%3 (对) 2.2%1 (错) 2%1.1(错) 2.2%1.1(错)
7 float = int/int 则除出来的数已经自动省掉了小数点后面的余数。如 f1=int1/1024,可以改为 f1=int1/1024.0
8.sleep()内的单位为秒,gcc编译,在头文件#include<unistd>中
9.若要获取运行程序进程号,linux除了通过ps指令外。还可以通过getpid函数,该函数也在unistd.h中
/*process.c*/
#include <unistd.h>
#include <pwd.h>
#include <sys/types.h>
#include <stdio.h>
int main(int argc, char **argv)
{
pid_t my_pid,parent_pid;
uid_t my_uid,my_euid;
gid_t my_gid,my_egid;
struct passwd *my_info;
my_pid = getpid();
parent_pid = getppid();
my_uid = getuid();
my_euid = geteuid();
my_gid = getgid();
my_egid = getegid();
}
10 strcmp函数使用strcmp("sundayhut",myname);注意不要写成strcmp("sundayhut\n",myname);
11 sscanf用法
sscanf(temp,"%s%s%s%s%s%s%s%[^\n]",last_major_minor,last_cpu_id,last_sequence_number,last_time,last_process_id,last_action,last_RWBS,last_detail);
读入文件形式如下:
8,0 0 1 0.000000000 2113 A W 38384096 + 8 <- (8,1) 38382048 8,1 0 2 0.000001649 2113 Q W 38384096 + 8 [blktrace_study] 8,1 0 3 0.000055171 2113 G W 38384096 + 8 [blktrace_study] 8,1 0 4 0.000234077 2113 P N [blktrace_study] 8,1 0 5 0.000362702 2113 I W 38384096 + 8 [blktrace_study] 8,1 0 0 0.000362704 0 m N cfq640 insert_request 8,1 0 0 0.000362705 0 m N cfq640 add_to_rr 8,0 0 6 0.000362707 2113 A W 38384104 + 8 <- (8,1) 38382056 8,1 0 7 0.000362709 2113 Q W 38384104 + 8 [blktrace_study]
%s能自动过滤掉空格,%[^\n]可以读入行直到行尾部
12.若open函数用O_DIRECT方式fd=open("/home/systemtap_study/dir1/25.txt", O_RDWR | O_CREAT | O_DIRECT);
则在*.c文件中需要
#define __USE_GNU
且编译时需要加上-D_GNU_SOURCE
gcc -o out code.c -D_GNU_SOURCE
13.打印unsigned long
unsigned long block;
printk("new block %lu\n",block);
14.编译错误
编译出现如下错误
/home/tss/share/7-7/printk-pcmfs/pcmfs/pcmfs/inode.c:417: warning: ISO C90 forbids mixed declarations and code
iso c90 不允许混合使用声明和代码
解决方法是,printk语句不能再变量声明前使用
例如:void fun()
{
printf("This is a strange World!\n");
int i;
char buf[128];
}
改正方法:
void fun()
{
int i;
char buf[128];
printf("This is a strange World!\n");
}
最近越发感叹一个好的工具的重要性。之前画图一直用visio2007版。这软件相比以前直接用office画流程图之类好用太多。但昨天想画一个光盘库的图,弄了好久也觉得画得不满意。visio2007中画平行四边形的图形都没有,还得一笔一划的画。。。。无语。。。不过还是硬着头皮给画了几个。
今日看到了老师画的三维图,跟我的相比高大上哇!!后缀是.vsdx(我以前visio2007年版的默认后缀为.vsd)。果断自己装了一个2013版的visio。我想说好用多了!!各种方便。。。以下是我画的图
我这画的是一个光盘匣,顺便提示一下:最右边那一竖我原本最后才画上,因此遮挡了光盘。通过如下置于底层的选项我把它放到了弹出的光盘下方:

开始->置于底层
最近这段时间写了两篇国内的专利,在专利格式、模板上哇自己也花了心思琢磨了一下,下面是我的一点心得,分享给大家。
以下部分的[]表示该内容可要可不要。()()表示表述该段话的不同形式
首先呢,你打开一片已经申请好的专利,会发现它由一下几个部分组成,
1.说明书摘要
2.摘要附图
3.权利要求书
4.技术领域
5.背景技术
6.发明内容
7.附图说明
8.具体实施方式
9.附图
这九个部分,其中部分3:权利要求书 是不需要我们写的,也就是你写好其余内容,专利中心处理专利的工作人员会根据你提交的内容帮你写好该篇专利需要保护的点。
下面一个一个部分的说书写时的模板要求
1,摘要。
本发明涉及。。。领域,公开了一种。。。的方法、装置。然后用简洁的语言具体描述该专利的核心思想。[说明该专利的优点]
2.摘要附图
用一张最能概括本专利核心的图
3.权利要求书
如上,这一部分可以不写
4.技术领域
(本发明涉及。。。领域)(本实用例属于。。。领域),[具体涉及。。。]
5.背景技术
从以下三个步骤递进写这一部分:5.1介绍该专利涉及的背景。5.2如今现有的技术、实现方式。5.3如今现有技术、实现方式的不足、缺点,从而导出本专利
6.发明内容
[第一段可以有 本发明的目的是。。。本发明优点]
本发明的技术方案是:。。。ps该部分的内容需要层层递进,即可先总写。然后再起一段,对上一段进行展开说明,再起一段的格式如下:(上述)(所述)。。。具体指。。。例子:本发明的技术法案是一种。。。的装置,该装置包括。。、。。和。。,分别粗略介绍包括的内容。该段完毕!然后另起几段写所述。。。进行详细介绍
[若专利分为技术和方法两部分,则有如下内容 本专利提供一种。。。的方法,具体步骤包括如下:。。。]
本发明的优先是:1、2、3、4.。。ps该部分与现有的技术比较,尽量多例如优点
7.附图说明
附图说明为对最后部分附图中的每一张图的描述,因为最后一部分的附图中每一张图都只表明了图1、图2、等,而没标明图的名字。
8.具体实施方式
其实这部分的内容就是结合附图说明把第6部分:发明内容的东西重新叙述一遍。特备要注意一下几点:
8.1该部分内容的叙述顺序应该严格与第6部分内容的叙述顺序对应。比如说先说读、再说写、最后说擦除。
8.2该部分要结合附图,若附图中有流程图,则要在流程图中标明步骤标记,在具体实施方式部分中进行流程说明时要引用附图中流程图的标记。若类似于工业设计,则要在工业设计图中标注零件的,则要在具体实施方式部分中提及零件、部件名字时要引用图中的标记。
8.3该部分最后要说明类似如下文字:“对于充分说明的本发明来说,还可具有多种变化及改型的实施方案,并不局限于上述实施方式的具体实施例。上述实施例仅仅作为本发明的说明,而不是对本发明的限制。总之,本发明的保护范围应包括哪些对本领域普通技术人员来说显而易见的边或或替代以及改型。”也就是扩大保护范围。
说到这里就分享完啦~~~希望对大家有帮助
1.安装
方法一:直接用指令sudo apt-get install fio
方法二:如果方法一不可行则,在官网http://freshmeat.net/projects/fio/下载fio的安装包。安装方法很简单。解压缩后,进入目录输入./configure make make install。不同压缩格式的解压书指令不同,具体请参考如下eoiioe博客:
http://www.cnblogs.com/eoiioe/archive/2008/09/20/1294681.html
2.测试注意点
可以先把设备mount到文件加上,如
mkdir /mnt/sdb1-mount
mount /dev/sdb1 /mnt/sdb1-mount。
mount上之后可以进行如下测试(ps:你如果想看mount成功了没,直接mount后回车,可以看到mount的东西):
注意 fio测试指令需要在root权限下才能操作
fio -filename=/mnt/sdb1-mount/text -direct=1 -rw=read -bs=1m -size=5G -numjobs=4 -runtime=10 -group_reporting -name=test_read
第一个text是运行完后在/mnt/sdb1-mount目录下会生成一个5G的text文件。
第二个text_read是测试运行结果在屏幕上显示的都是以test_read:。。。
3.关于参数:
-filename 后可以直接加设备名 如-filename /dev/sdb1 ;也可以加设备的挂载点的文件名,如上述例子。
size 读写的总大小
bs blocksize 每次读写的大小
-direct=1 测试绕过机器自带的buffer,测试结果更真实
-rw的5中情况 1.-rw=read 2.-rw=randread 3.-rw=write 4.-rw=randwrite 5.-rw=randrw -rwmixread=70 //混合模式下读占百分之70
numjobs=4 本次测试的线程数为4
ioengine=sync io引擎的方式为同步。通常有同步和异步两种方式。同步的io一次只能发出一个io请求,等待内核完成才返回,这样对单线程来说iodepth总是小于1的,但多个线程并发可以使iodepth变大。异步方式就是一次提交一批请求,等待一批的完成,减少交互的次数
-group_reporting 关于现实结果,汇总每个进程的信息
4注意:.若将设备挂载在虚拟硬盘上,即ram*,那么注意,-size的值不能过大,因为分配的ram大小是固定的,若-size的大小超过了系统分配你ram的大小,则会出现error。error信息如下:
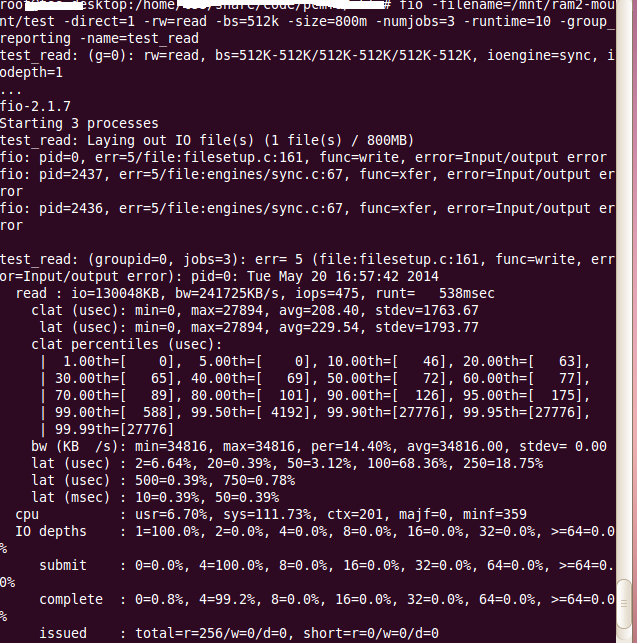
这时相当于ram被弄崩了~此时,你需要1.umount;2.重新格式化ram*;3.重新挂载
5.关于测试脚本
[global] direct=1 #use raw io instead of buffered io numjobs=1 #number of clones of processes/threads for each job ioengine=sync #libaio is asynchronized io mode, sync is synchronized mode iodepth=1 #if use libaio, iodepth means the ios can be submitted at the same time. It is important! (Can be thought as number of thread/process in sync io mode) iodepth_batch_complete=0 #how often to check request completion for libaio. #iodepth_low=4 #if io queue is full, wait completion until depth reach this. runtime=200 #in seconds for each job thread #use thread instead of process filename=/home/test.bin #the device/file name size=10M rw=randwrite [BS:1K] bs=1k [BS:2K] stonewall #wait until the previous job is finished bs=2k [BS:4K] stonewall #wait until the previous job is finished bs=4k [BS:8K] stonewall #wait until the previous job is finished bs=8k [BS:16K] stonewall #wait until the previous job is finished bs=16k [BS:32K] stonewall #wait until the previous job is finished bs=32k [BS:64K] stonewall #wait until the previous job is finished bs=64k [BS:128K] stonewall #wait until the previous job is finished bs=128k [BS:256K] stonewall #wait until the previous job is finished bs=256k [BS:512K] stonewall #wait until the previous job is finished bs=512k
其中globle为全局共享参数;[BS:1K]为运行打印出代码的名字
假设该文件保存名字为runfiotest.ini,则运行指令为
fio runfiotest.ini
6测试结果
下面给出一段测试结果
BS:1K: (groupid=0, jobs=1): err= 0: pid=2467: Wed May 21 15:52:27 2014
read : io=10240KB, bw=13456KB/s, iops=13455, runt= 761msec
clat (usec): min=0, max=2018, avg=66.88, stdev=28.71
lat (usec): min=0, max=2018, avg=67.90, stdev=29.56
clat percentiles (usec):
| 1.00th=[ 0], 5.00th=[ 62], 10.00th=[ 62], 20.00th=[ 63],
| 30.00th=[ 63], 40.00th=[ 66], 50.00th=[ 66], 60.00th=[ 67],
| 70.00th=[ 67], 80.00th=[ 67], 90.00th=[ 70], 95.00th=[ 87],
| 99.00th=[ 131], 99.50th=[ 143], 99.90th=[ 278], 99.95th=[ 314],
| 99.99th=[ 756]
bw (KB /s): min=13290, max=13290, per=98.77%, avg=13290.00, stdev= 0.00
lat (usec) : 2=3.03%, 4=0.01%, 10=0.02%, 20=0.08%, 50=0.21%
lat (usec) : 100=93.09%, 250=3.43%, 500=0.11%, 750=0.01%, 1000=0.01%
lat (msec) : 4=0.01%
cpu : usr=18.95%, sys=80.53%, ctx=32, majf=0, minf=11
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=50.0%, 4=50.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued : total=r=10240/w=0/d=0, short=r=0/w=0/d=0
latency : target=0, window=0, percentile=100.00%, depth=1
blocksize,iops,bw的关系。块大小(bw)*每秒io次数(iops)= 带宽(bw)
注意read : io=10240KB, bw=13456KB/s, iops=13455, runt= 761msec这一行:
当配置文件设置的runtime小于761ms时,则read的io量达不到10240K,所以说一个测试正常结束有两个原因:1.io达到了配置文件的需要io操作的大小,即size值。2.运行达到了设置的时间。
故若你想保证运行时间足够长,可以不设置runtime的值。
其中
read : io=10240KB, bw=13456KB/s, iops=13455, runt= 761msec
io表示本次请求的大小io=10240KB 可以看出我们上面设的size=10M相对应。当然也存在runtime时间用完了,而fio未运行完毕,这是io小于size值,而runt 等于设定的runtime
总体介绍如下
io=执行了多少Mio
bw=bandwith表示带宽。
iops表示每秒的io数量
slat 提交延时
clat 表示complete lantency 完成延时
lat 表示 响应延时
cpu 利用率
IO depth io队列
IO submit 单个IO提交的IO数
IO complet 单个IO完成的IO数??
IO issued 读、写下发的请求书。and how many of them were short
IO lantencies=IO完成的延时分布
IO=总共执行了多少size的IO
aggrb=group总带宽
minb=最小平均带宽
maxb=最大平均带宽
mint=group中线程最短运行时间
maxt=group中线程最长运行时间
ios=所有group总共执行的IO数
merge=总共噶生的IO合并数
ticks=Number of ticks we kept the disk busy
in_queue=在队列中花的时间
util=磁盘利用率
以上参数参考
http://blog.csdn.net/yuesichiu/article/details/8722417
若用ram模拟硬盘测试,会发现以上五项的值都为0。而在/home目录下做fio测试就不会为0了
6.关于格式化ram后的ext4测试 & 基于/home目录下(ext4文件系统)的fio测试。
虽然都是ext4文件系统,但是ram的内存模拟硬盘,而/home是直接在硬盘下跑,故ram的测试结果中bw iops 要比/home下大很多,运行时间小很多。
今天第一次使用再生龙。
再生龙这款软件可以进行整个硬盘的赋值,也就是说如果你要装很多台机子,那么你可以先把其中一台装好,补丁打好、内核神马的都编译好后,直接使用再生龙。这样就不用每台机子都进行复杂的配置了。以下是使用的step
step1:下载再生龙的镜像。一个iso文件,它就相当于linux ,windows的镜像一样,之后要用软件将这个再生龙镜像做成启动盘。
step2:利用做镜像的软件,将下载的再生龙镜像做到U盘中
step3:在只插母盘的状态下,利用做好的U盘,从U盘启动。目的在于记录母盘的编号。
step4:同时将母盘和要被复制的盘插到电脑上,从U盘启动,根据提示选相关选项。目的有一个步骤是选定一个母盘,则选择的是step3观察到的母盘的编号。选错了很惨的。这样会使得东西拷贝反了。
注意:
1母盘和被复制的盘貌似有要求,母盘大小貌似要与被复制的盘相等。
2用U盘做好再生龙镜像后,从U盘启动,若没有对应的再生龙界面,则是引导盘没做好。这可能是你做镜像软件的问题
3保证被复制的盘是一个可以用的好盘。可以按住DEL进入BIOS选项后,在boot的device那里看识别了几个device。。我今天就搞了半天,结果要被复制的盘是个坏盘,咿咿呀呀。。.
Host by is-Programmer.com | Power by Chito 1.3.3 beta | Theme: Aeros 2.0 by TheBuckmaker.com