bio:代表了一个io请求
request:一个request中包含了一个或多个bio,为什么要有request这个结构呢?它存在的目的就是为了进行io的调度。通过request这个辅助结构,我们来给bio进行某种调度方法的排序,从而最大化地提高磁盘访问速度。
request_queue:每个磁盘对应一个request_queue.该队列挂的就是request请求。
具体如下图:(有颜色方框头表示数据结构的名字)
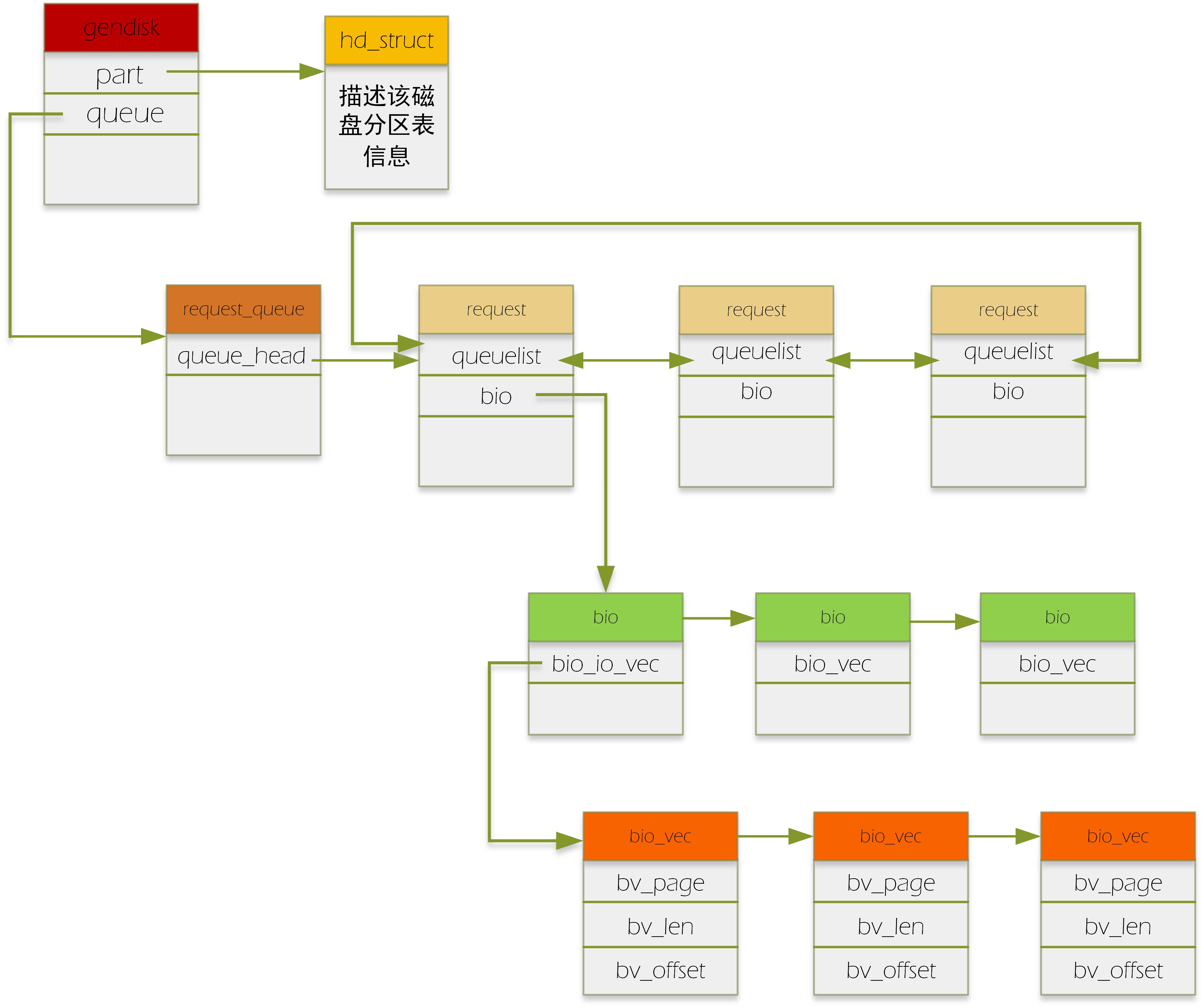
请求到达block层后,通过generic_make_request这个入口函数,在通过调用一系列相关的函数(具体参见我另一篇博客)把bio变成了request。具体的做法如下:如果几个bio要读写的区域是连续的,即积攒成一个request(一个request上挂多个连续的bio,就是我们通常说的“合并bio请求”),如果一个bio跟其他的bio都连不上,那它就自己创建一个新的request,把自己挂在这个request下。当然,合并bio的个数也是有限的,这个可以通过配置文件配置。
对于上段补充一点:上层的一次请求可能跨越了多个扇区,形成不连续的扇区段,那么该请求构造的每个bio对应着一个连续的扇区段。故一个请求可以构造出多个bio。
合并后的request放入每个设备对应的request_queue中。之后设备驱动调用peek_request从request_queue中取出request,进行下一步处理。
这里要注意的是,在实现设备驱动时,厂家可以直接从request_queue中拿出排队好的request,也可以实现自己的bio排队方法,即实现自己的make_request_fn方法,即直接拿文件系统传来的bio来自己进行排队,按需设计,想怎么排就怎么排,像ramdisk,还有很多SSD设备的firmware就是自己排。(这里就和我另一篇博客,说到为什么generic_make_request要设计成一层递归调用联系起来)。
网上有个问答也是我的疑惑:这里我写一遍,加强记忆
bio结构中有bio_vec数组结构,该结构的的数组可以指向不同的page单元,那为什么不在bio这一级就做了bio合并工作,即把多个bio合并成一个bio,何必加入一个request这么麻烦?
答:每个bio有自己的end_bio回调,一旦一个bio结束,就会对自己进行收尾工作,如果合并了,或许有些bio会耽误,灵活性差。
参考博客:
http://blog.csdn.net/flyingcloud_2008/article/details/5818995
2018年11月01日 21:31
Helpful post
2018年11月01日 21:32
good tutorial
2021年8月30日 00:12
I really appreciate this wonderful post that you have provided for us. I assure this would be beneficial for most of the people.
2021年9月25日 05:21
In this case you will begin it is important, it again produces a web site a strong significant internet site:
2022年8月10日 17:54
Instagram PVA Accounts
Thanks for your information. It was really very helpful.
2022年8月10日 18:03
Gmail PVA Accounts
This is a great inspiring article. I am pretty much pleased with your good work. You put really very helpful information.
2022年8月10日 18:12
Buy Gmail PVA Accounts
I recently found much useful information on your website, especially this blog page. Among the lots of comments on your articles. Thanks for sharing.
2022年8月10日 18:36
Buy Instagram PVA Accounts
Thanks for posting this info. I just want to let you know that I just check out your site and I find it very interesting and informative. I can't wait to read lots of your posts.
2022年8月12日 16:45
Instagram PVA Accounts
I high appreciate this post. It’s hard to find the good from the bad sometimes. but I think you’ve nailed it! would you mind updating your blog with more information?
2022年9月06日 18:49
Bihar Board Model Paper 2023 Class 7 Pdf Download with Answers for English Medium, Hindi Medium, Urdu Medium & Students for Small Answers, Long Answer, Very Long Answer Questions, and Essay Type Questions to Term1 & Term2 Exams at official website. BSEB Question Paper Class 7 New Exam Scheme or Question Pattern for Sammittive Assignment Exams (SA1 & SA2): Very Long Answer (VLA), Long Answer (LA), Small Answer (SA), Very Small Answer (VSA), Single Answer, Multiple Choice and etc.
2022年9月27日 18:24
hair beauty products online
I am no expert. But I believe you just made an excellent point. You certainly fully understand what you are speaking about. and I can truly get behind that.
2022年10月16日 23:08
Nice to be visiting your blog again. It has been months for me. Well, this article that I've been waiting for so long. I need this article to complete my assignment in college and it has the same topic as your article. Thanks. Great share.
2022年11月01日 02:40
Thanks for the post and great tips. Even, I also think that hard work is the most important aspect of getting success.
2022年11月20日 04:19
Are you looking for an expert private detective agent for counter surveillance? Foglight Private Investigation is the once can help you with it.<a href='https://foglightpi.com/services/counter-surveillance/'>Counter Surveillance </a>
2022年11月25日 01:16
office space for rent
This is a great inspiring article. I am pretty much pleased with your good work. You put really very helpful information.
2022年11月25日 21:15
UX/UI Consultancy
Excellent and very exciting site. Love to watch. Keep Rocking.
2022年11月26日 04:12
Chicago Web Design
This is the first time I am visiting here. I found so much interesting stuff in your blog, especially its discussion. From the tons of comments on your articles. I guess I am not the only one having all the enjoyment here! Keep up the good work.
2022年12月16日 04:44
laser hair removal safety glasses
I highly appreciate this post. It’s hard to find the good from the bad sometimes. but I think you’ve nailed it! would you mind updating your blog with more information?
2022年12月16日 19:07
Excellent and very exciting site. Love to watch. Keep Rocking.
2022年12月21日 19:26
In computer science, a request queue is a data structure used to store requests waiting to be processed. Requests are typically added to the Coronavirus Vaccines end of the queue, and processed from the front. This ensures that all requests are processed in the order in which they were received.
2022年12月27日 04:41
Your blog was found very well and I can get all the information that I need, If you are looking to get more interesting content visit Foglight Investigations GM Blogger GM Web Solutions
2023年1月07日 01:16
Fox Hills Realty offers a wide variety of real estate services including buying, selling, and leasing properties. We have experts in every field to help you with all of your needs.
2023年2月23日 04:53
Flood & Water Damage Repair
Very interesting post. This is my first-time visiting here. I found so much interesting stuff in your blog, especially its discussion. Thanks for the post!
2023年2月27日 12:23
QuickBooks Time is one of the best tools offered by QuickBooks to make employee schedules, track in and out times and more.
Sometimes, users can face QuickBooks Time Login Issues. A number of reasons could cause this issue. Visit our website for our troubleshooting guide for quickbooks time login
2023年2月27日 18:54
hey you wrote well ! Also visit my blog
<a href="https://mnsdigitalflip.com/best-guest-post-marketplaces-for-seo-experts/">guest post marketplace</a>
2023年2月27日 20:11
I believe other website owners should take this site as an example, very clean, has an amazing style, and has a user-friendly design.
2023年3月01日 17:56
Interesting and curious information on this topic can be found here. The profile is worth a look.
2023年3月19日 23:17
Jamaica all inclusive resorts
The information you have posted is very useful. The sites you have referred were good. Thanks for sharing.
2023年3月22日 18:33
I’d must consult you here. Which is not some thing It’s my job to do! I spend time reading an article that may get people to think. Also, many thanks for permitting me to comment.
2023年3月23日 00:15
anunturi matrimoniale
This is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value of providing a quality resource for free.
2023年3月31日 20:31
Your current posts always contain a lot of very timely information. Where did you come up with that? I'm just saying that you are very inspiring. Thanks again
2023年4月02日 03:53
Nice to be visiting your blog again. It has been months for me. Well, this article that I've been waiting for so long. I need this article to complete my assignment in college and it has the same topic as your article. Thanks. Great share.
2023年4月07日 05:14
corporate lawyer brisbane
The website is looking a bit flashy and it catches the visitor's eyes. The design is pretty simple and has a good user-friendly interface.
2023年4月16日 21:12
Nice to be visiting your blog again. It has been months for me. Well, this article that I've been waiting for so long. I need this article to complete my assignment in college and it has the same topic as your article. Thanks. Great share.
2023年4月18日 06:51
https://fumigar-plagas-sevilla.es/eliminar-termitas-exterminar-termitas-matar-termitas-en-sevilla/
Hello, I have browsed most of your posts. This post is probably where I got the most useful information for my research. Thanks for posting. Maybe we can see more on this. Are you aware of any other websites on this subject?
2023年4月23日 01:39
I really appreciate this wonderful post that you have provided for us. I assure you this would be beneficial for most people.
2023年4月23日 13:25
Excellent article. Very interesting to read. I really love to read such a nice article. Thanks! Keep rocking.
2023年4月24日 15:40
Thanks for the post and great tips. Even, I also think that hard work is the most important aspect of getting success.
2023年5月11日 03:06
puzzle games online
Hello, I have browsed most of your posts. This post is probably where I got the most useful information for my research. Thanks for posting. Maybe we can see more on this. Are you aware of any other websites on this subject?
2023年5月19日 02:07
Decentralised Commerce
The information you have posted is very useful. The sites you referred were good. Thanks for sharing this.
2023年7月22日 13:49
Well researched and written content. I got such a amazing information from the post. I will also say that design of the website is nice and loaded quickly.
2023年9月12日 13:37
The best thing about this blog is that it is completely informative and solve all my doubt regards this topic. Your other blogs in this category are also amazing. Your content writers are doing great research before writing the content, kudos to them.
2023年9月13日 13:40
Nice Post, That solve my all doubts. Keep Posting.
2023年12月06日 00:44
Learning Books for Kenyan Children
Please share more like that. Thanks for this great post.
2024年1月23日 16:05
It is imperative that we read blog posts very carefully. I am already done with it and find that this post is really amazing.
2024年1月29日 04:00
Pregnancy u shaped pillow
Thank you for taking the time to publish this information very useful.
2024年1月29日 18:37
This is such a great resource that you are providing and you give it away for free. I love seeing websites that understand the value of providing a quality resource for free. It is the old what goes around comes around routine.
2024年2月06日 15:25
Spinal Cord Stimulator Trial
The website is looking a bit flashy and it catches the visitor's eyes. The design is pretty simple and has a good user-friendly interface.
2024年2月09日 15:23
I read that Post and got it fine and informative. Please share more like that.
2024年2月13日 05:26
الربح من تجارة العملات في العراق
Thanks for the tips and information. I really appreciate it.
2024年2月27日 17:49
PVA Instagram Accounts
I am enjoying your website. You have some great insight and great stories.
2024年4月28日 15:06
Edmonton Cleaning Services
Great info! I recently came across your blog and have been reading along. I thought I would leave my first comment. I don’t know what to say except that I have.