在linux系统中fdisk -l可以看到所有磁盘的分区情况。含有系统的分区有 * 号标志,如下:
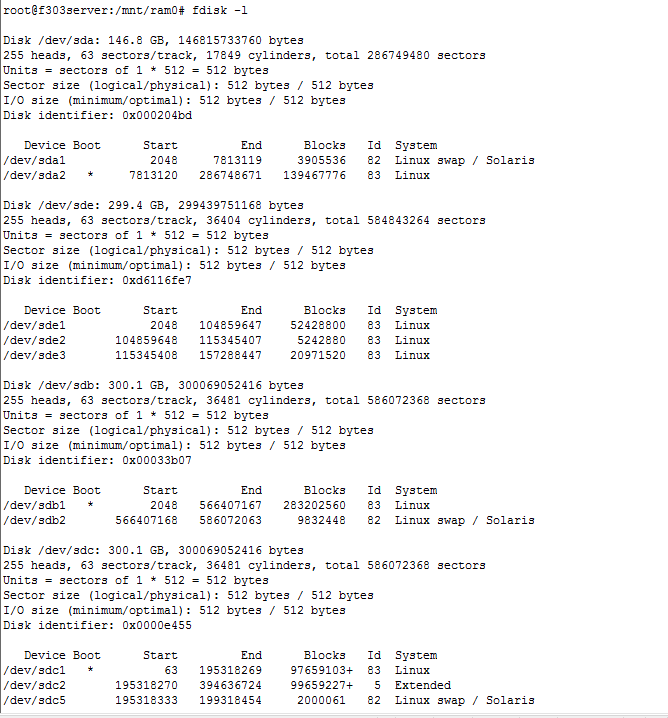
分区太多,上图为显示完全。但在已经显示的分区中,多个分区的Boot列中都有* 号标志,那么当前的系统是运行在哪个分区的呢?
注意:根目录所在的分区就是当前系统所在的分区。输入 df -h,可以观察到根目录所在的分区。
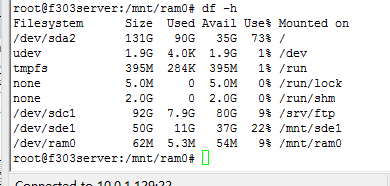
如上图所示:与根目录相应的分区为/dev/sda2,故当前系统运行在分区/dev/sda2上。
在linux系统中fdisk -l可以看到所有磁盘的分区情况。含有系统的分区有 * 号标志,如下:
分区太多,上图为显示完全。但在已经显示的分区中,多个分区的Boot列中都有* 号标志,那么当前的系统是运行在哪个分区的呢?
注意:根目录所在的分区就是当前系统所在的分区。输入 df -h,可以观察到根目录所在的分区。
如上图所示:与根目录相应的分区为/dev/sda2,故当前系统运行在分区/dev/sda2上。
先给出两个makefile相关链接:
http://www.yayu.org/book/gnu_make/make-04.html
http://www.yayu.org/book/gnu_make/make-06.html
例1:linux-2.6.34.14\fs\ext2\makefile详解
# # Makefile for the linux ext2-filesystem routines. # obj-$(CONFIG_EXT2_FS) += ext2.o ext2-y := balloc.o dir.o file.o ialloc.o inode.o \ ioctl.o namei.o super.o symlink.o ext2-$(CONFIG_EXT2_FS_XATTR) += xattr.o xattr_user.o xattr_trusted.o ext2-$(CONFIG_EXT2_FS_POSIX_ACL) += acl.o ext2-$(CONFIG_EXT2_FS_SECURITY) += xattr_security.o ext2-$(CONFIG_EXT2_FS_XIP) += xip.o
1.obj-$(CONFIG_EXT2_FS) += ext2.o obj- 表示如何编译 y m n分别表示进入内核编译,m 模块编译,n不编译。其中$(CONFIG_EXT2_FS)表示取CONFIG_EXT2_FS值操作,所以ext2的编译方式取决于编译内核是make config时CONFIG_EXT2_FS选定的值。
2.ext2-y或者ext2-objs都表示ext2模块(注:-objs用法见例二)
3.:= 表示赋值操作
4.ext2-y := balloc.o dir.o file.o ialloc.o inode.o \
5.+= 表示追加方式复值:
objects = main.o foo.o bar.o utils.o
objects += another.o
上边的两个操作之后变量“objects”的值成:“main.o foo.o bar.o utils.o another.o”。使用“+=”操作符,就相当于:
objects = main.o foo.o bar.o utils.o
objects := $(objects) another.o
6.ext2-$(CONFIG_EXT2_FS_XATTR) += xattr.o xattr_user.o xattr_trusted.o 表示如果make config步骤中CONFIG_EXT2_FS_XATTR赋值为y,则ext2模块在前面的编译基础上再加上xattr.o xattr_user.o xattr_trusted.o三个文件。
7ext2-$(CONFIG_EXT2_FS_POSIX_ACL) += acl.o
# # Makefile for the Linux pcmfs filesystem routines. # obj-m += simplefs.o simplefs-objs := bitmap.o itree_common.o namei.o inode.o file.o dir.o KERNELDIR:=/usr/src/linux-2.6.34.14/ PWD:=$(shell pwd) default: make -C $(KERNELDIR) M=$(PWD) modules clean: rm -rf *.o *.mod.c *.ko *.symvers
1.obj-m直接指定编译方式为模块化
2.simplefs-objs := bitmap.o itree_common.o namei.o inode.o file.o dir.o 其中-objs为模块。表示simplefs.o模块依赖后面的文件。
3.KERNELDIR:=/usr/src/linux-2.6.34.14/ 将变量KERNELDIR赋值,为后面提供使用
4.PWD:=$(shell pwd)赋值为当前目录
5.make -C $(KERNELDIR) M=$(PWD) modules
其中make的 -C表示转换路径,可以再linux下通过man make查看:
-C dir, --directory=dir
这是一篇论文的阅读笔记,这个论文讲的是测试Android系统的一个工具链
AndroStep consists of workload generator:Mobibench and workload analyzer: MOST
我们关注的是MOST
3.2 MOST:Moblie Storage Analyzer
MOST consist of (i)a modified Linux kernel that maintins processes and file-related information for IOs;(ii)a block analyzer that enables identification of a file for a given block,(iii)blktrace utility
the information nedds to be collected from different layer.MOST collects the IOtrace at the block device driver level to deduces the file information and then it process information for each respective block.MOST addresses three reverse-mapping issue:LBA-to-file,LBA-to-process and retrospective LBA mapping
1.LBA-to-file即使用debugfs实现
2.LBA-to-process :create a process-to-block mapping table.the entry of the table is <LBA,process id>.When the IO scheduler inserts the IO request into the queue,MOST inserts the<LBA,process id>information into the process-to-block mapping table.当后期给出一个LBA,可以通过这个table可以用重新获得process id
3.retrospectve LBA mapping.In Android,many files are shortlives and are created and rapidly delete by SQLite.They are fsync()ed to NAND storage.We need file information for a given LBA when a trace is recored not when posthumously analyzed.但MOST准备分析一个LBA时,这个文件也许都已经被删掉了。怎么解决这个问题呢:MOST 创建了一个file-to-block的表,表的每一项是<LBA,FILE>.当IO调度器plugs in the LBA to the 调度队列,MOST向表中插入一项<LBA,FILE>,之后通过给定的LBA再在这个表里查需要的信息。为了减小表的大小。只为temporary file向表中插入信息。
Mobile Storage Analyzer的输出:
IO完成时间。
读or写
IO大小和扇区号
进程编号、进程名字
Block类型,元数据块、日志块or数据块
数据块存放文件的名字
1.debugfs由block编号推导存放的具体文件(包括目录的数据)
icheck block编号
ncheck inode编号
在我的另一篇博客上:http://sundayhut.is-programmer.com/posts/49173.html
有详细过程
2.debugfs查看文件(包括目录的数据)所存放的block号
该功能即1的逆向查找
查看文件stat filename
查看目录stat dirname
这里有一点要注意,使用stat查找文件时,一定要使用挂载文件目录的相对路径,否则会出现一下问题:
File not found by ext2_lookup
怎么解决呢?看如下例子:
我将/dev/sdd1挂载到/mnt/sdd1上。输入debugfs /dev/sdd1后,若要查看/mnt/sdd1目录下的ext2_256M文件,你应该输入
stat ext2_256M或者stat ./ext2_256M
而不应该输入:
stat /mnt/sdd1/ext2_256M
截图入下:
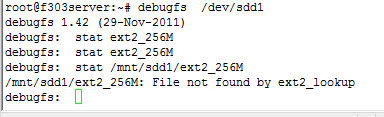
正确的输入stat ext2_256M后,屏幕上显示如下:
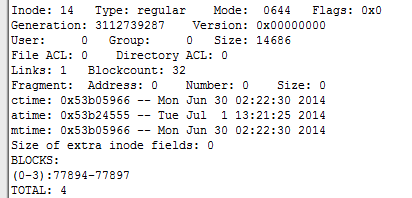
其中BLOCKS:后面为stat查看数据所占的块号!!注意是块号,而不是扇区号。。人家都写了BLOCKS了,怎么会以为是扇区号呢。
其中倒数第二行的(0-3)表示其第0到第3个数据块所对应的块号
3.恢复刚刚误删的文件
确定要删除的文件在哪个分区上,比如我删除的文件在/mnt/sde1目录下文件,根据我的挂载目录的习惯,我知道这个分区是/dev/sde1,接下来就用stat的lsdel显示最近删除的东西,以及dump指令来恢复
lsdel
dump <inode号> path 其中inode号在lsdel时会显示。path是你想恢复的路径
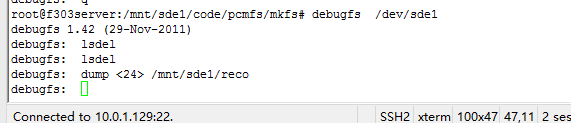
4.关于ls,在debugfs中,输入ls和ls -l,分别有如下显示:
输入ls:
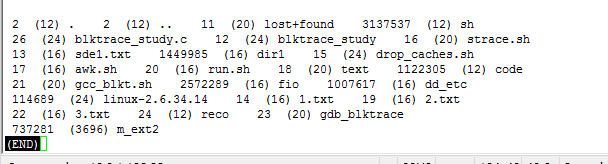
上图中每个文件或者目录项对应着3个项,如 737281 (3696) m_ext2
其中737281为inode号,括号中数字含义不明。
ls -l显示如下
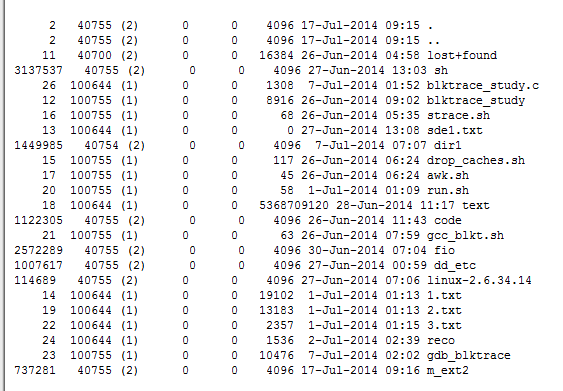
以m_ext2来分析
其中第一列737281为inode编号,4096为size,第2、3、4、5列含义不明。有知道的读者忘指教~
1.cat /proc/cpuinfo 查看cpu型号、频率
2.cat /proc/meminfo 查看内存大小
3.dmidecode -t memory 查看DDR2 DDR3
4.cat /etc/issue 查看Ubuntu版本
5.cat /proc/version 查看内核版本
6.uname -a 查看linux位数 x86_64为64位,其余32位。
参考博文:
http://www.cnblogs.com/joeblackzqq/archive/2011/04/11/2013010.html
函数原型
fopen:返回的是FILE *
FILE * fopen(const char * path,const char * mode);
open:返回的是int
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
两者区别
1.返回值
fopen返回FILE * ,是ANSIC标准中的c语言库函数,可理解为对open的一层封装。返回的是文件流,因为设备不可以当成流式文件,故设备的打开只可以用open。
open返回int,open是系统调用,返回文件句柄,文件的句柄是文件在文件描述符表中的索引。open可以打开设备,也可以打开普通文件。
2.缓冲机制
fopen有缓冲机制,使用FILE这个结构保存缓冲数据。open没有缓存机制,每次读操作都直接从文件系统获取数据。简单来说:fopen有缓冲,open无缓冲
缓冲文件系统特点:在内存开辟一个“缓冲区”,为程序每一个文件使用,读写都要经过缓冲区。
非缓冲文件系统:借助文件结构体指针对文件进行管理,依赖于操作系统,是系统级的输入输出,不设文件结构体指针
3.fopen是在open的基础上扩充而来的,大多数情况用fopen
4.fopen与 fread和 fwrite配合使用。open与read,write配合使用
5.fopen属于高级IO,open属于低级IO
6.一般用fopen打开普通文件,open打开设备文件
7.fopen 可移植,open不能
本文参考:
http://jesserei.blog.163.com/blog/static/121411689201032015129673/
http://blog.csdn.net/liangxanhai/article/details/7749170
函数原型
int fsync(int fd);
sync();
函数区别:
sync函数将所有修改过的块缓冲区排入写队列,然后返回,不等待实际写磁盘操作
fsync只对参数中的文件描述符fd指定的单一文件起作用,并且等待写磁盘操作结束,在返回。故fsync可以应用于数据库这样程序,这种应用程序需要确保将修改过的块立即写到磁盘上。
本文参考:
http://blog.csdn.net/wallwind/article/details/7461701
首先来看O_DIRECT参数适用要求:
O_DIRECT
Try to minimize cache effects of the I/O to and from this file. In general this will degrade performance, but it is useful in special situations, such as when applications do their own caching. File I/O is done directly to/from user space buffers. The I/O is synchronous, i.e., at the completion of a read(2) or write(2), data is guaranteed to have been transferred. Under Linux 2.4 transfer sizes, and the alignment of user buffer and file offset must all be multiples of the logical block size of the file system.
上述也就是说buffer的地址以及大小都必须是block size 的整数倍,buffer的大小可以通过代码设定,但buffer的首地址的控制,需要通过posix_menalign()函数来数据对齐
ps:上述所说的buffer地址为block size整数倍,就是数据对齐的概念
int posix_memalign (void **memptr, size_t alignment, size_t size);
成功会返回size字节的动态内存,且内存地址为alignment的整数倍
下面看具体代码
#define __USE_GNU
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include <unistd.h>
#include <pwd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main(void)
{
int fd;
int i;
const int SIZE = 4096*10;//(每次写入文件数据块大小)
char* buffer;
char s[100];
int pagesize=getpagesize();
printf("pagesize = %d\n",pagesize);
pid_t my_pid;
my_pid=getpid();
printf("%d\n",my_pid);
if(mkdir("dir1",S_IRWXU|S_IRGRP|S_IXGRP|S_IROTH)<0)//创建新目录
{
printf("mkdir failed\n");
return -1;
}
if(0 != posix_memalign((void**)&buffer, 4096, 40960)){
printf("Errori in posix_memalign\n");
}
for(i=0;i<10;i++)
{
sprintf(s,"./dir1/aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa%d.txt",i);
printf("%s\n",s);
fd=open(s, O_RDWR | O_CREAT | O_DIRECT);
write(fd,buffer,SIZE);
fsync(fd);
close(fd);
}
free(buffer);
sync();
return 0;
}
上述代码有几个点:
1.mkdir创建目录
2.posix_menalign()进行数据对齐
3.获取block size,即内存页大小getpagesize()
4.编译时需要gcc -o blktrace_study1 blktrace_study1.c -D_GNU_SOURCE
5.open函数返回的为int ,区别fopen函数返回FILE *
6.fsync和sync区别见另一篇博客
问题描述:在umount时遇到下面问题
umount /mnt/sdd1:device is busy.
(In some cases useful info about processes that use the device is found by losf(8) or fuser(1))
解决方法:
一开始我使用ps查看正在运行进程,kill -9 也没有强制杀死,后来用了下述方法,成功搞定:
step1:fuser -m -v /mnt/sdd1 查看到底哪些进程使用了/mnt/add1
-m 指定路径表示的是一个磁盘挂载的目录或者磁盘分区
-v 指定fuser结果显示的格式
step 2:fuser -m -v -i -k /mnt/sdd1 杀死使用了/mnt/add1设备的进程
-k kill 杀死与/mnt/sdd1相关的进程
-i interactive .交互式的,该参数在Kill process时交互式询问用户是否要kill进程
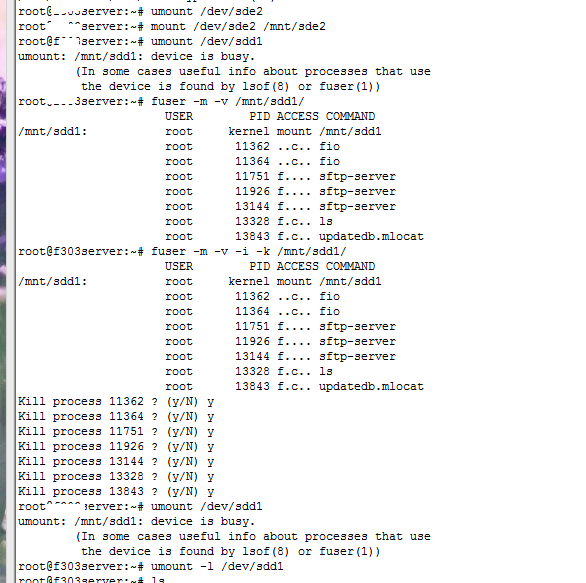
问题与解决的截图如下:
补充一句:umount时若device is busy.你可以试试umount -l /dev/sdd1
其中-l是lazy的含义。man mount
Host by is-Programmer.com | Power by Chito 1.3.3 beta | Theme: Aeros 2.0 by TheBuckmaker.com